목표
자바의 멀티쓰레드 프로그래밍에 대해 학습하세요.
학습할 것 (필수)
- Thread 클래스와 Runnable 인터페이스
- 쓰레드의 상태
- 쓰레드의 우선순위
- Main 쓰레드
- 동기화
- 데드락
개념정리
프로세스(Process)
- 사전적 의미 : 일의 과정이나 공정
- 실행중인 프로그램을 의미
- 프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)을 할당받아 프로세스가 됨
쓰레드(Thread)
- 프로세스라는 작업공간에서 실제로 작업을 처리하는 일꾼
- 프로세스의 자원을 이용해서 작업을 수행함
- 모든 프로세스에는 최소한 하나 이상의 쓰레드가 존재
- 쓰레드가 하나(싱글 쓰레드)
- 둘 이상의 쓰레드(멀티 쓰레드)
멀티 태스킹(multi-tasking)
- 대부분의 OS가 지원함
- 여러 개의 프로세스가 동시에 실행될 수 있는것을 말함
멀티 쓰레딩(multi-threading)
하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것.
CPU의 코어(core)가 한 번에 단 하나의 작업만 수행할 수 있으므로, 실제로 동시에 처리되는 작업의 개수와 일치합니다.
대부분 쓰레드의 수는 코어의 개수보다 훨씬 많기 때문에 각 코어가 아주 짧은 시간 동안 여러 작업을 번갈아 가며 수행함으로써 여러 작업들이 모두 동시에 수행되는 것처럼 보이게합니다.
따라서 프로세스의 성능이 단순하게 쓰레드의 개수에 비례하는것은 아니며, 하나의 쓰레드를 가진 프로세스보다 두개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수 있습니다.
멀티 쓰레딩의 장점
- CPU의 사용률을 향상시킨다
- 자원을 보다 효율적으로 사용할 수 있다
- 사용자에 대한 응답성이
- 작업이 분리되어 코드가 간결해진다.
멀티 쓰레딩에서 주의할 점(신경써야 할 점?)
여러 쓰레드가 같은 프로세스 내에서 자원을 공유하면서 작업을 하기 때문에 발생할 수 있는 동기화(synchronization), 교착상태(deadlock) 과 같은 문제들을 고려해서 신중히 프로그래밍 해야합니다.
동기화(synchronization)와 교착상태(deadlock)에 대해서는 밑에서 자세히 다루도록 하겠습니다.
자바에서의 쓰레드
JVM을 사용하면 응용 프로그램이 동시에 실행되는 여러 쓰레드를 가질 수 있습니다.
모든 쓰레드에는 우선순위가 있습니다. 우선 순위가 높은 쓰레드가 낮은 쓰레드보다 우선적으로 실행됩니다.
각 쓰레드는 데몬 쓰레드로 마크되거나 마크되지 않을 수 있습니다.
(데몬 쓰레드는 사용자 쓰레드를 보조하는 쓰레드입니다. 대표적으로 자바의 Garbage Collector가 데몬 쓰레드 입니다.)
일부 쓰레드에서 실행중인 코드가 새로운 Thread 객체를 생성할 때 새로운 쓰레드는 자신을 생성한 쓰레드의 우선 순위와 동일하게 설정된 우선 순위를 가지며 생성 쓰레드가 데몬쓰레드인 경우 데몬 쓰레드가 됩니다.
JVM이 시작될 때 일반적으로 하나의 쓰레드가 있습니다.
(main 메서드의 작업을 수행하는 것도 쓰레드 / 쓰레드 이름이 main 이다.)
JVM은 다음중 하나가 발생할때 까지 쓰레드를 유지합니다..
- Runtime클래스의 종료 메소드가 호출되었으며 보안관리자(security manager)가 종료 조작이 발생하도록 허용할 때
- 데몬 쓰레드가 아닌 모든 쓰레드는 실행된 후 run() 메소드의 작업이 끝나거나 run 메소드 이외에서 예외를 throw 했을 때 종료됩니다.
모든 쓰레드에는 식별 목적으로 이름이 있습니다.
둘 이상의 쓰레드가 동일한 이름을 가질 수 있습니다.
쓰레드가 생성될 때 이름이 지정되지 않은 경우 새 이름이 생성됩니다.
("Thread-숫자" 형식으로 생성됩니다. 숫자는 0부터 시작해서 생성할 때 마다 1씩 증가합니다.)
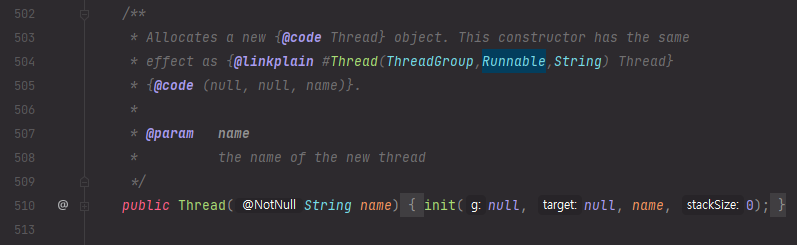
달리 명시되지 않는 한, 이 클래스의 생성자 또는 메서드에 null 인수를 전달하면 NullPointerException이 throw됩니다. 아래는 Thread 생성자의 인자로 null 값을 넣었을 때의 예제 입니다.


아래는 Thread 클래스의 생성자들 중 하나와 init() 메소드 입니다.
init 메소드를 보면 매개변수 중 name 값이 null 이면 NullPointException을 던지는 것을 확인할 수 있습니다.

Java 에서 쓰레드를 생성하는 방법
자바에서 쓰레드를 생성하는 방법에는 두 가지가 있습니다.
1. Thread 클래스를 상속받는 방법
클래스를 Thread의 자식 클래스로 선언하는 것입니다.
자식 클래스는 실행 메소드(run 메소드)를 재정의 해야합니다.
그런 다음 클래스의 인스턴스를 할당하고 실행할 수 있습니다.
아래는 Thread 클래스를 상속받아 만든 MyThread 클래스 예제입니다.


2. Runnable 인터페이스를 구현하는 방법
클래스를 Runnable 인터페이스를 구현하는 클래스로 선언하는 것입니다.
그런 다음 해당 클래스는 run() 메소드를 구현합니다.
run() 메소드를 구현했다면 클래스의 인스턴스를 할당하고 Thread를 만들 때 인수로 전달하고 시작할 수 있습니다.
아래는 Runnable을 구현해서 만든 쓰레드 예제 입니다.


Runnable 인터페이스를 구현한 경우, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 Thread클래스의 생성자의 매개변수로 제공해야 합니다. 아래의 코드는 실제 Thread 클래스의 소스코드 (Thread.java)를 이해하기 쉽게 수정한 것입니다.
인스턴스 변수로 Runnable 타입의 변수 r을 선언해 놓고 생성자를 통해서 Runnable 인터페이스를 구현한 인스턴스를 참조하도록 되어 있는 것을 확인할 수 있습니다. 그리고 run() 을 호출하면 참조변수 r을 통해서 Runnable 인터페이스를 구현한 인스턴스의 run()이 호출됩니다.
public class Thread {
private Runnable r; // Runnable을 구현한 클래스의 인스턴스를 참조하기 위한 변수
public Thread(Runnable r) {
this.r = r;
}
public void run() {
if (r != null)
r.run(); // Runnable 인터페이스를 구현한 인스턴스의 run()을 호출
}
....
}
위의 쓰레드를 구현하는 두가지 방법 중에서 어느 쪽을 선택해서 쓰레드를 구현해도 별 차이는 없지만
Thread클래스를 상속받으면 다른 클래스를 상속받을 수 없기 때문에, Runnable 인터페이스를 구현하는 방법이 일반적입니다.
Runnable 인터페이스를 구현하는 방법은 재사용성(reusablilty)이 높고 코드의 일관성(consistency)을 유지할 수 있기 때문에 보다 객체지향적인 방법이라 할 수 있습니다.
쓰레드를 구현한다는 것은, 위의 두 방법 중 어떤 것을 선택하든지, 그저 쓰레드를 통해 작업하고자 하는 내용으로 run()의 몸통 {} 을 채우는 것일 뿐입니다.
Thread 클래스와 Runnable 인터페이스
Thread 클래스와 Runnable인터페이스를 이용해서 쓰레드를 구현할 수 있다는걸 위에서 알아봤습니다.
이제 Thread 클래스와 Runnable 인터페이스의 내부적인 코드에 대해 보겠습니다..
Runnable 인터페이스
Runnable 인터페이스는 함수형 인터페이스(@FuntionalInterface)로 run() 추상메소드 하나만이 존재합니다.
구현하는 클래스에서 run() 메소드를 구현하는걸로 쓰레드에게 작업할 내용을 설정할 수 있습니다.
아래는 Java 8 버전의 Runnable 인터페이스 입니다.
함수형 인터페이스로 run() 추상메소드 하나만 가지고 있는것을 확인할 수 있습니다.

Thread 클래스
필드
실제 Thread 클래스안에는 많은 필드가 존재하지만 public 접근 제어자인 필드는 단 3개만 존재합니다.
모두 쓰레드의 우선 순위에 대한 상수 필드인데 3가지는 다음과 같습니다.
- public final static int MIN_PRIORITY = 1
쓰레드가 가질 수 있는 우선 순위의 최소값입니다. - public final static int NORM_PRIORITY = 5
쓰레드가 가지는 기본 우선 순위 값입니다. - public final static int MAX_PRIORITY = 10
쓰레드가 가질 수 있는 우선 순위의 최대값입니다.
생성자
생성자를 살펴보기 앞서 Thread 생성자에서 인자들이 가지는 의미를 먼저 정리하고 넘어가겠습니다.
String gname : 쓰레드를 (이름을 지정하지 않고)생성할 때 자동으로 생성되는 이름입니다 자동으로 생성되는 이름은 "Thread-" + n 의 형식을 가집니다.(여기서 n은 정수입니다)
String name : 쓰레드 생성자에 인자로 주는 새로운 쓰레드의 이름을 의미합니다.
Runnable target : target은 쓰레드가 시작될 때 run() 메소드가 호출될 객체입니다.
ThreadGroup group : group은 생성할 쓰레드를 설정할 쓰레드 그룹입니다. group 값이 null 이면서 보안 관리자(security manager)가 존재한다면 그룹은SecurityManager.getThreadGroup() 에 의해서 결정됩니다. 보안 관리자가 없거나, SecurityManager.getThreadGroup() 이 null을 반환한다면 현재 쓰레드의 그룹으로 설정됩니다.
long stackSize : 새로운 쓰레드의 스택 사이즈를 의미합니다. 0이면 이 인자는 없는것과 같습니다.
stackSize는 가상 머신이 스레드의 스택에 할당 할 주소 공간의 대략적인 바이트 수입니다.
- public Thread()
기본 생성자로 Thread(null, null, gname)과 같습니다.
(group = null, target = null, gname) 을 의미 - public Thread(Runnable target)
이 생성자는 Thread(null, target, gname) 과 같습니다. - public Thread(ThreadGroup group, Runnable target)
이 생성자는 Thread(group, target, gname)과 같습니다. - public Thread(String name)
이 생성자는 Thread(null, null, name)과 같습니다. - public Thread(ThreadGroup group, String name)
이 생성자는 Thread(group, null, name)과 같습니다. - public Thread(Runnable target, String name)
이 생성자는 Thread(null, target, name)과 같습니다. - public Thread(ThreadGroup group, Runnable target, String name)
새로 생성 되는 쓰레드는 자신을 생성하는 쓰레드(현재 실행중인 쓰레드)와 같은 우선순위를 가집니다.
우선순위는 setPriority 메소드를 이용해서 변경 가능합니다.
새로 생성 되는 쓰레드는 자신을 생성하는 쓰레드가 데몬 쓰레드로 마크된 경우에만 데몬 쓰레드로 마크됩니다.
setDaemon 메소드를 사용해서 쓰레드가 데몬 쓰레드인지 여부를 변경할 수 있습니다. - public Thread(ThreadGroup group, Runnable target, String name, long stackSize)
stackSize인자로 받는것을 빼면 Thread(ThreadGroup group, Runnable target, String name) 생성자와 같습니다.
stackSize 값을 0으로 하면 Thread(ThreadGroup group, Runnable target, String name)와 똑같이 동작합니다.
이 생성자의 동작은 플랫폼에 따라 다르기 때문에 사용시 극도의 주의를 기울여야합니다.
주어진 계산을 수행하는 데 필요한 스택 크기는 JRE 구현마다 다를 수 있습니다.
이러한 변화를 고려하여 스택 크기 매개 변수를 신중하게 조정해야 할 수 있으며 응용 프로그램이 실행될 각 JRE구현에 대해 조정을 반복해야 할 수 있습니다.
If there is a security manager, its checkAccess method is invoked with the ThreadGroup as its argument.
In addition, its checkPermission method is invoked with the RuntimePermission("enableContextClassLoaderOverride") permission when invoked directly or indirectly by the constructor of a subclass which overrides the getContextClassLoader or setContextClassLoader methods.
Thread 생성자로 새로운 쓰레드를 생성할 때 쓰레드 그룹 인자와 SecurityManager간의 관계에 대한 내용인데
SecurityManager 클래스가 무엇인지 이해해야 해당 내용을 이해할 수 있을것 같습니다.
메소드
구현과 실행에 관련된 run() 메소드와 start() 메소드
public void run() : 쓰레드가 실행되면 run() 메소드를 호출하여 작업을 합니다.
public synchronized void start() : 쓰레드를 실행시키는 메소드 입니다. start 메소드가 호출되었다고 해서 바로 실행되는 것이 아니라, 일단 실행 대기 상태에 있다가 자신의 차례가 되어야 실행됩니다.
run() 메소드와 start() 메소드의 차이점
쓰레드를 시작할 때 run() 메소드를 호출하면 되는것 같은데 실제로는 start() 메서드를 호출해서 쓰레드를 실행합니다.
main메소드에서 run() 메소드를 호출하는 것은 생성된 쓰레드를 실행시키는 것이 아니라 단순히 메소드를 호출하는 것입니다. 반면에 start() 메소드를 호출하면 새로운 쓰레드가 작업을 실행하는데 필요한 새로운 호출 스택(call stack)을 생성한 다음에 run()을 호출합니다. 즉, 새로 생성된 호출 스택에 run()이 첫 번째로 올라가게 합니다. run() 메소드의 수행이 종료된 쓰레드는 호출스택이 모두 비워지면서 생성된 호출 스택도 소멸됩니다.
아래는 각각 main메소드에서 run 메소드를 호출했을 때와 main메소드에서 start 메소드를 호출했을 때를 그림으로 나타낸 예제입니다.


한 번 실행이 종료된 쓰레드는 다시 실행 할 수 없습니다. 즉, 하나의 쓰레드에 대해 start()가 한 번만 호출될 수 있다는 뜻입니다. 하나의 쓰레드 객체에 대해 start() 메소드를 두 번 이상 호출하면 실행시에 IllegalThreadStateException이 발생합니다.


다음과 같이 start 메소드를 두번 호출하는 경우는 정상적으로 실행됩니다.
첫번째 쓰레드를 실행한 뒤 또 다른 새로운 쓰레드를 생성해서 실행하기 때문입니다.
MyThread_1 th1 = new MyThread_1();
th1.start()
th1 = new MyThread_1();
th1.start()
코드를 치다가 생긴 의문이 main 쓰레드에서 예외가 발생했을 때 다른 스레드도 함께 종료되나? 라는것이었습니다.
아래 예제의 실행 결과를 보면 에러 메세지를 찍어주면서 번갈아가며 만들었던 쓰레드도 실행되고 있는것을 확인했습니다. 결국 생성했던 쓰레드는 끝까지 수행한 뒤 종료됐습니다.
한 쓰레드에서 예외가 발생해서 종료하더라도 다른 쓰레드의 실행에는 영향을 미치지 않는다는걸 확인했습니다.

쓰레드의 스케줄링과 관련된 메소드
| 메서드 | 설 명 |
| static void sleep(long millis) static void sleep(long millis, int nanos) |
지정된 시간(1/1000초 단위)동안 쓰레드를 일시정지 시킨다. 지정한 시간이 지나고 나면, 자동적으로 다시 실행 대기 상태가 됩니다. |
| void join() void join(long millis) void join(long millis, int nanos) |
지정된 시간동안 쓰레드가 실행되도록 한다. 지정된 시간이 지나거나 작업이 종료되면 join()을 호출한 쓰레드로 다시 돌아와 실행을 계속합니다. |
| void interrupt() | 쓰레드에게 작업을 멈추라고 요청합니다. 쓰레드의 interrupted상태를 false에서 true로 변경합니다. |
| static boolean interrupted() | sleep()이나 join()에 의해 일시정지 상태인 쓰레드를 깨워서 실행대기상태로 만듭니다. 해당 쓰레드에서는 InterruptedException이 발생함으로써 일시정지상태를 벗어나게 됩니다. |
| @Deprecated void stop() | 쓰레드를 즉시 종료시킵니다. |
| @Deprecated void suspend() | 쓰레드를 일시정지 시킵니다. resume()을 호출하면 다시 실행 대기상태가 됩니다. |
| @Deprecated void resume() | suspend()에 의해 일시정지 상태에 있는 쓰레드를 실행대기 상태로 만듭니다. |
| static void yield() | 실행 중에 다신에게 주어진 실행시간을 다른 쓰레드에게 양보(yield)하고 자신은 실행 대기상태가 됩니다. |
스케줄링과 관련된 메소드들은 아래의 쓰레드의 상태에서 더욱 자세하게 다루겠습니다.
이외의 메소드들
- currentThread() : 현재 실행중인 thread 객체의 참조를 반환합니다.
- destroy() : clean up 없이 쓰레드를 파괴합니다. @Deprecated 된 메소드로 suspend()와 같이 교착상태(deadlock)을 발생시키기 쉽습니다.
- isAlive() : 쓰레드가 살아있는지 확인하기 위한 메소드 입니다. 쓰레드가 시작되고 아직 종료되지 않았다면 살아있는 상태입니다.
- setPriority(int newPriority) : 쓰레드의 우선순위를 새로 설정할 수 있는 메소드입니다.
- getPriority() : 쓰레드의 우선순위를 반환합니다.
- setName(String name) : 쓰레드의 이름을 새로 설정합니다.
- getName(String name) : 쓰레드의 이름을 반환합니다.
- getThreadGroup() : 쓰레드가 속한 쓰레드 그룹을 반환합니다. 종료됐거나 정지된 쓰레드라면 null을 반환합니다.
- activeCount() : 현재 쓰레드의 쓰레드 그룹 내의 쓰레드 수를 반환합니다.
- enumerate(Thread[] tarray) : 현재 쓰레드의 쓰레드 그룹내에 있는 모든 활성화된 쓰레드들을 인자로 받은 배열에 넣습니다. 그리고 활성화된 쓰레드의 숫자를 int 타입의 정수로 반환합니다.
- dumpStack() : 현재 쓰레드의 stack trace를 반환합니다.
- setDaemon(boolean on) : 이 메소드를 호출한 쓰레드를 데몬 쓰레드 또는 사용자 쓰레드로 설정합니다.
JVM은 모든 쓰레드가 데몬 쓰레드만 있다면 종료됩니다. 이 메소드는 쓰레드가 시작되기 전에 호출되야합니다. - isDaemon() : 이 쓰레드가 데몬 쓰레드인지 아닌지 확인하는 메소드입니다. 데몬쓰레드면 true, 아니면 false 반환
- getStackTrace() : 호출하는 쓰레드의 스택 덤프를 나타내는 스택 트레이스 요소의 배열을 반환합니다.
- getAllStackTrace() : 활성화된 모든 쓰레드의 스택 트레이스 요소의 배열을 value로 가진 map을 반환합니다. key는 thread 입니다.
- getId() : 쓰레드의 고유값을 반환합니다. 고유값은 long 타입의 정수 입니다.
- getState() : 쓰레드의 상태를 반환합니다.
쓰레드의 상태
효율적인 멀티쓰레드 프로그램을 만들기 위해서는 보다 정교한 스케줄링을 통해 프로세스에게 주어진 자원과 시간을 여러 쓰레드가 낭비없이 잘 사용하도록 프로그랭 해야합니다.
때문에 쓰레드의 스케줄링을 잘하기 위해서는 쓰레드의 상태와 관련된 메소드를 잘 알아야 합니다.
쓰레드의 상태
NEW : 쓰레드가 생성되고 아직 start()가 호출되지 않은 상태
RUNNABLE : 실행 중 또는 실행 가능한 상태
BLOCKED : 동기화 블럭에 의해서 일시정지된 상태(lock이 풀릴 때까지 기다리는 상태)
WAITING, TIMED_WAITING : 쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은(unrunnable) 일시정지 상태, TIMED_WAITING은 일시정지시간이 지정된 경우를 의미한다.
TERMINATED : 쓰레드의 작업이 종료된 상태
아래 그림은 쓰레드의 생성부터 소멸까지의 모든 과정을 그린것입니다.

1. 쓰레드를 생성하고 start()를 호출하면 바로 실행되는 것이 아니라 실행 대기열에 저장되어 자신의 차례가 될 때까지 기다려야 합니다. (실행 대기열은 큐(queue)와 같은 구조로 먼저 실행대기열에 들어온 쓰레드가 먼저 실행됩니다.
2. 자기 차례가 되면 실행상태가 됩니다.
3. 할당된 실행시간이 다되거나 yield() 메소드를 만나면 다시 실행 대기상태가 되고 다음 쓰레드가 실행상태가 됩니다.
4. 실행 중에 suspend(), sleep(), wait(), join(), I/O block에 위해 일시정지상태가 될 수 있습니다.
(I/O block은 입출력 작업에서 발생하는 지연상태를 말합니다. 사용자의 입력을 받는 경우를 예로 들수 있습니다.)
5. 지정된 일시정지시간이 다되거나, notify(), resume(), interrupt()가 호출되면 일시정지상태를 벗어나 다시 실행 대기열에 저장되어 자신의 차례를 기다리게 됩니다.
6. 실행을 모두 마치거나 stop()이 호출되면 쓰레드는 소멸됩니다.
쓰레드의 상태와 스케줄링에 관련된 메소드들
sleep()
public static void sleep(long millis) : 지정된 시간동안 쓰레드를 멈추게 합니다.(millis, 1/1000초 단위)
public static void sleep(long millis, int nanos) : (millis, 1/1000초 단위,nanos 1/1000000000초 단위==10억분의 1초)
- 밀리세컨드와 나노세컨드의 시간단위로 세밀하게 값을 지정할 수 있지만 어느 정도의 오차가 발생할 수 있다는 것은 염두에 둬야 합니다.
- sleep()에 의해 일시정지 상태가 된 쓰레드는 지정된 시간이 다 되거나 interrupt()가 호출되면(InterruptedException 발생시킴), 잠에서 깨어나 실행대기 상태가 됩니다.
- sleep()을 호출할 때는 항상 try-catch문으로 interruptedException을 예외처리 해줘야 합니다.
- sleep()은 항상 현재 실행 중인 쓰레드에 대해 작동합니다. 때문에 static으로 선언되어 있으며 참조변수를 이용해서 호출하기 보다는 Thread.sleep(2000)과 같이 호출해야 합니다.
아래 예제는 th1 과 th2 두개의 쓰레드를 생성해 th1객체에 sleep() 메소드를 호출하여 th1 쓰레드의 작업을 4초간 멈추려고 한 코드입니다. th1을 일시정지 상태로 뒀기 때문에 th1 쓰레드가 가장 먼저 종료될것 으로 예상했지만 실제로는 main 메서드가 가장 늦게 종료됩니다. th1.sleep(4000)과 같이 호출해도 실제로 영향을 받는 것은 main메소드를 실행하는 main 쓰레드 입니다.


interrupt()
public void interrupt() : 쓰레드의 interrupted상태를 false에서 true로 변경, 쓰레드에게 작업을 멈추라고 요청합니다. 요청을 할 뿐 쓰레드를 강제로 종료시키는 것은 아닙니다.
public boolean isInterrupted() : 쓰레드의 interrupted상태를 반환, interrupt()가 호출되었는지 확인하는데 사용할 수 있지만, interrupted()와 달리 interrupted상태를 false로 초기화하지 않습니다.
public static boolean interrupted() : 현재 쓰레드의 interrupted상태를 반환 후, false로 변경. 쓰레드가 sleep(), wait(), join() 에 의해 '일시정시 상태(WAITING)'에 있을 때, 해당 쓰레드에 대해 interrupt()를 호출하면, sleep(), wait(), join()에서 interruptedException이 발생하고 쓰레드는 '실행대기 상태(RUNNABLE)'로 바뀝니다.
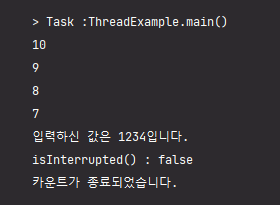
아래는 interrupt()와 isInterrupted()를 사용해서 카운트 다운 도중에 사용자의 입력이 들어오면 카운트 다운을 종료하는 코드 입니다. 사용자의 입력이 끝나면 interrupt()에 의해 카운트다운이 중간에 멈추게 됩니다.



아래는 이전의 코드의 시간 지연을 위한 for문 대신 Thread.sleep(1000)으로 1초 동안 지연하도록 변경한 코드입니다. 사용자가 입력을 완료해도 카운트는 종료 되지 않는데 이것은 Thread.sleep(1000) 에서 InterruptedException이 발생했기 때문입니다. sleep()에 의해 멈춰 있을 때 interrupt() 를 호출하면 InterruptedException이 발생하고 쓰레드의 Interrupted 상태는 false로 자동 초기화 됩니다.


이런 상황에서 사용자의 입력을 받을때 카운트다운을 종료하려면 catch 블럭에 interrupt()를 추가로 넣어줘서 쓰레드의 interrupted상태를 true로 다시 바꿔줘야 합니다.
try {
Thread.sleep(1000);
}catch (InterruptedException e) {
interrupt();
}
suspend(), resume(), stop()
suspend() : sleep()처럼 쓰레드를 일시정지 합니다.
resume() : suspend()에 의해 일시정지 상태에 있는 쓰레드를 실행대기 상태로 만듭니다.
stop() : 호출되는 즉시 쓰레드가 종료됩니다.
suspend(), resume(), stop()은 쓰레드의 실행을 제어하는 가장 손쉬운 방법이지만, suspend()와 stop()이 교착상태(deadlock)를 일으키기 쉽게 작성되어 있으므로 이 메소드들은 모두 '@Deprecated' (사용이 권장되지 않음)됐습니다.
yield()
쓰레드 자신에게 주어진 실행시간을 다음 차례의 쓰레드에게 양보(yield)합니다.
예를들어 스케쥴러에 의해 1초의 실행시간을 할당받은 쓰레드가 0.5초의 시간동안 작업한 상태에서 yield()가 호출되면, 나머지 0.5초는 포기하고 다시 실행 대기 상태가 됩니다.
yield()와 interrupt()를 적절히 사용하면, 프로그램의 응답성을 높이고 보다 효율적인 실행이 가능하게 할 수 있습니다.
아래의 코드는 yield() 와 interrupt()를 이용해서 효율성과 응답성을 높인 코드입니다.
만약 suspend() 를 호출해서 suspended가 true 라면 run() 메소드의 while문을 의미없이 계속 돌게 됩니다(바쁜 대기상태 / busy-waiting). 이 때 yield 메소드를 else 문에 추가함으로써 남은 시간을 낭비하지 않고 다른 쓰레드에게 차례를
양보(yield)합니다.
또한 while문 안의 Thread.sleep(1000)에 의해 쓰레드가 일시정지 상태에 머물러 있는 상황이라면 stopped의 값이 true로 바뀌었어도 쓰레드가 정지될 때까지 최대 1초의 시간지연이 생길 수 있습니다. stop()에 th.interrupt() 를 추가함으로써 sleep()에서 InterruptedException이 발생하여 즉시 일시정지 상태에서 벗어나게 되므로 응답성이 좋아집니다.
public class ThreadExample {
public static void main(String[] args) {
MyThread_1 th1 = new MyThread_1("쓰레드1");
MyThread_1 th2 = new MyThread_1("쓰레드2");
MyThread_1 th3 = new MyThread_1("쓰레드3");
th1.start();
th2.start();
th3.start();
try {
Thread.sleep(2000);
th1.suspend();
Thread.sleep(2000);
th2.suspend();
Thread.sleep(2000);
th1.resume();
Thread.sleep(2000);
th1.stop();
th2.stop();
Thread.sleep(2000);
th3.stop();
}catch (InterruptedException e) { }
}
}
class MyThread_1 implements Runnable {
boolean suspended = false;
boolean stopped = false;
Thread th;
MyThread_1(String name) {
th = new Thread(this, name); // Thread(Runnable target, String name)
}
@Override
public void run() {
String name = th.getName();
while (!stopped) {
if (!suspended) {
System.out.println(name);
try {
Thread.sleep(1000);
}catch (InterruptedException e) {
System.out.println(name + " - interrupted");
}
} else {
Thread.yield(); // suspended 가 true 일때 쓰레드의 남은시간을 양보해줌
} // 만약 Thread.yield()가 없다면 쓰레드는 남은 시간을 아무런 일도 하지않는 while 문을 돌며 낭비하게됨
}
System.out.println(name + " - stopped");
}
public void suspend() {
suspended = true;
th.interrupt();
System.out.println(th.getName() + " - interrupt() by suspend()");
}
public void stop() {
stopped = true;
th.interrupt();
System.out.println(th.getName() + " - interrupt() by stop()");
}
public void resume() { suspended = false; }
public void start() { th.start(); }
}
join()
쓰레드 자신이 하던 작업을 잠시 멈추고 다른 쓰레드가 지정된 시간동안 작업을 수행하도록 할 때 사용합니다.
public void join()
public void join(long millis)
public void join(long millis, long nanos)
시간을 지정하지 않으면, 해당 쓰레드가 작업을 모두 마칠 때까지 기다립니다.
작업중에 다른 쓰레드의 작업이 먼저 수행되어야할 필요가 있을 때 join()을 사용합니다.
join 메소드도 sleep 메소드처럼 interrupt()에 의해 대기상태에서 벗어날 수 있으며, join()이 호출되는 부분을 try-catch문으로 감싸서 InterruptedException을 catch 해야합니다.
sleep()과 다른점
join()은 현재 쓰레드가 아닌 특정 쓰레드에 대해 동작하므로 static메소드가 아니라는 것입니다.
아래의 코드는 JVM의 가비지 컬렉터(Garbage collector)를 흉내 내어 간단히 구현한 것입니다.
최대 메모리가 1000인 상태에서 사용된 메모리가 60%를 초과한 경우 gc 쓰레드가 깨어나서 메모리는 비우는 작업을 합니다. 이때 만약 join이 없는 상태로 한다면 main쓰레드는 계속해서 메모리를 늘려가고 최악의 경우 1000이 넘었는데도 계속 해서 메모리를 쌓을 수 있습니다. 이때 gc.join()을 사용해서 gc가 작업할 시간을 주고 main 쓰레드는 지정된 시간동안 대기하는것이 필요합니다.
public class ThreadExample {
public static void main(String[] args) {
MyThread_1 gc = new MyThread_1();
gc.setDaemon(true);
gc.start();
int requiredMemory = 0;
for (int i = 0; i < 20; i++) {
requiredMemory = (int)(Math.random() * 10) * 20;
// 필요한 메모리가 사용할 수 있는 양보다 크거나 전체 메모리의 60%이상을
// 사용했을 경우 gc를 깨웁니다.
if (gc.freeMemory() < requiredMemory || gc.freeMemory() < gc.totalMemory() * 0.4) {
gc.interrupt(); // 잠자고 있는 gc를 깨운다.
try {
gc.join(100); // join() 을 호출해서 gc가 작업할 시간을 주고 main 쓰레드는 기다립니다.
}catch (InterruptedException e) {
}
}
gc.usedMemory += requiredMemory;
System.out.println("usedMemory:" + gc.usedMemory);
}
}
}
class MyThread_1 extends Thread {
final static int MAX_MEMORY = 1000;
int usedMemory = 0;
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000 * 10);
}catch (InterruptedException e) {
System.out.println("Awaken by interrupt().");
}
gc(); // garbage collection을 수행합니다.
System.out.println("Garbage Collected. Free Memory : " + freeMemory());
}
}
public void gc() {
usedMemory -= 300;
if (usedMemory < 0) usedMemory = 0;
}
public int totalMemory() { return MAX_MEMORY; }
public int freeMemory() { return MAX_MEMORY - usedMemory; }
}
쓰레드의 우선순위
쓰레드는 우선순위(priority)라는 속성(멤버변수)을 가지고 있는데, 이 우선순위의 값에 따라 쓰레드가 얻는 실행시간이 달라집니다.
-> 쓰레드가 수행하는 작업의 중요도에 따라 쓰레드의 우선순위를 다르게 지정하여 특정 쓰레드가 더 많은 작업시간을 갖도록 할 수 있습니다.
예를들어 파일전송기능이 있는 메신저의 경우, 파일다운로드를 처리하는 쓰레드보다 채팅내용을 전송하는 쓰레드의 우선순위가 더 높아야 사용자가 채팅을 하는데 불편함이 없을 것입니다. (대신 파일 전송에 걸리는 시간은 더 길어집니다.)
쓰레드의 우선순위를 지정하는 필드와 메소드
- public final static int MIN_PRIORITY = 1
쓰레드가 가질 수 있는 우선 순위의 최소값입니다. - public final static int NORM_PRIORITY = 5
쓰레드가 가지는 기본 우선 순위 값입니다. - public final static int MAX_PRIORITY = 10
쓰레드가 가질 수 있는 우선 순위의 최대값입니다. - setPriority(int newPriority) : 쓰레드의 우선순위를 지정한 값으로 변경합니다.
- getPriority() : 쓰레드의 우선순위를 반환합니다.
쓰레드가 가질 수 있는 우선순위의 범위는 1~10이며 숫자가 높을수록 우선순위가 높습니다.
생성한 쓰레드의 우선순위는 쓰레드를 생성한 쓰레드로부터 상속받습니다.
main 메소드를 수행하는 쓰레드는 우선순위가 5이므로 main메소드 내에서 생성하는 쓰레드의 우선순위는 기본적으로 5가 됩니다.
아래 코드는 두개의 쓰레드의 우선순위를 다르게 설정하는 예제입니다.
setPriority() 메소드는 쓰레드를 시작하기 전에만 우선순위를 변경할 수 있습니다.
public class ThreadExample {
public static void main(String[] args) {
MyThread_1 th1 = new MyThread_1();
MyThread_2 th2 = new MyThread_2();
th1.setPriority(1);
th2.setPriority(8);
System.out.println("Priority of th1(-) : " + th1.getPriority());
System.out.println("Priority of th2(|) : " + th2.getPriority());
th1.start();
th2.start();
}
}
class MyThread_1 extends Thread {
@Override
public void run() {
for (int i=0; i < 300; i++) {
System.out.print("-");
for (int x = 0; x < 2100000000; x++);
}
}
}
class MyThread_2 extends Thread {
@Override
public void run() {
for (int i=0; i < 300; i++) {
System.out.print("|");
for (int x = 0; x < 2100000000; x++);
}
}
}
Main 쓰레드
'Java의 실행환경인 JVM은 하나의 하나의 프로세스로 실행됩니다.'
이말은 곧 자바 애플리케이션이 기본적으로 하나의 메인 쓰레드를 가진다는 것입니다. Java 프로그램을 실행하기 위해 Main Thread는 main() 메소드를 실행합니다. main() 메소드는 메인 쓰레드의 시작점을 선언하는 것입니다.
메인 쓰레드는 자바에서 처음으로 실행되는 쓰레드이자 모든 쓰레드는 메인 쓰레드로 부터 생성됩니다.
메인 쓰레드가 종료되더라도 생성된 쓰레드가 실행 중 이라면 모든 쓰레드가 작업을 완료하고 종료될 때 까지 프로그램은 종료되지 않습니다. 즉, 실행중인 사용자 쓰레드가 하나도 없다면 프로그램은 종료됩니다.


데몬 쓰레드
다른 일반 쓰레드(사용자 쓰레드)의 작업을 돕는 보조적인 역할을 수행하는 쓰레드입니다. 사용자 쓰레드가 모두 종료되면 데몬 쓰레드는 강제적으로 자동 종료됩니다.
-> 데몬 쓰레드는 보조역할을 수행하므로 사용자 쓰레드가 모두 종료되고 나면 데몬 쓰레드의 존재는 의미가 없기 때문입니다.
이런 점을 제외하면 사용자 쓰레드와 차이는 없습니다.
데몬 쓰레드와 관련된 메소드
- isDaemon() : 쓰레드가 데몬인지 확인합니다. 데몬 쓰레드면 true, 아니면 false
- setDaemon() : 쓰레드를 데몬 쓰레드로 또는 사용자 쓰레드로 변경합니다. true면 데몬 쓰레드가 됩니다.
아래는 데몬 쓰레드를 지정하고 확인하는 코드입니다.

데몬 쓰레드의 예로는 Garbage Collector, 워드프로세서의 자동저장, 화면자동갱신 등이 있습니다.
동기화
싱글쓰레드 프로세스의 경우 프로세스 내에서 단 하나의 쓰레드만 작업하기 때문에 프로세스의 자원을 가지고 작업하는데는 별 문제가 없습니다.
멀티 쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 주게 됩니다. 아래는 두개의 쓰레드에서 공유 자원인 예금을 사용해서 입금하는 작업을 할 때 발생할 수 있는 문제입니다.

예금이 10만원인 통장에서 두 쓰레드가 각각 접근해서 10만원, 5만원을 입금해서 원래라면 35만원이 됐어야 하는데 예금이 최종적으로 저장된 예금은 20만원이 되는 큰일이 생겼습니다.
이렇게 공유 자원 접근 순서에 따라 실행 결과가 달라지는 프로그램의 영역을 임계구역(critical section)이라고 합니다.
예시에서 예금을 확인하고 입금한 뒤 저장하는 부분이 임계구역 입니다.
임계구역 해결 조건
- 상호 배제(mutual exclusion) : 한 쓰레드가 임계구역에 들어가면 다른 쓰레드는 임계구역에 들어갈 수 없습니다. 이것이 지켜지지 않으면 임계구역을 설정한 의미가 없습니다.
- 한정 대기(bounded waiting) : 한 쓰레드가 계속 자원을 사용하고 있어 다른 쓰레드가 사용하지 못한 채 계속 기다리면 안됩니다. 어떤 쓰레드도 무한 대기(infinite postpone)하지 않아야 합니다. 즉 특정 쓰레드가 임계구역에 진입하지 못하면 안됩니다.
- 진행의 융통성(progress flexibility) : 한 쓰레드가 다른 쓰레드의 작업을 방해해서는 안됩니다.
우리는 임계구역(critical section)과 잠금(lock)의 개념을 활용해서 한 쓰레드가 특정 작업을 마치기 전까지 다른 쓰레드에 의해 방해받지 않도록 할 수 있습니다.
공유 데이터를 사용하는 코드 영역을 임계구역으로 지정해놓고, 공유 데이터(객체)가 가지고 있는 lock을 획득한 단 하나의 쓰레드만 이 영역 내의 코드를 수행할 수 있게 합니다. 그리고 해당 쓰레드가 임계 구역내의 모든 코드를 수행하고 벗어나서 lock을 반납해야만 다른 쓰레드가 반납된 lock을 획득하여 임계구역의 코드를 수행할 수 있게 됩니다.
-> 마치 공공 장소의 화장실을 사용할 때 문을 잠그고 들어가서 일을 본 뒤 화장실 문을 열고 다음사람에게 차례를 넘겨주는것을 떠올리면 lock에 대한 이해가 쉽습니다.
이처럼 한 쓰레드가 진행 중인 작업을 다른 쓰레드가 간섭하지 못하도록 막는 것을 쓰레드의 동기화(synchronization)라고 합니다.
자바에서는 synchronized블럭을 이용해서 쓰레드의 동기화를 지원했지만,
JDK1.5부터는 'java.util.concurrent.locks'와 'java.util.concurrent.atomic'패키지를 통해서 다양한 방식으로 동기화를 구현할 수 있도록 지원하고 있습니다.
자바에서 의 동기화 처리방법
synchronized를 이용한 동기화
가장 간단한 동기화 방법으로 synchronized키워드를 이용해서 임계구역을 설정하는 방법입니다.
- 1. 메소드 전체를 임계구역으로 지정.
메소드가 호출된 시점부터 lock을 얻어서 작업하고 메소드가 종료되면 lock을 반환합니다.
public synchronized void calcSum() {
....
} - 2. 특정한 영역을 임계구역으로 지정
참조변수는 lock을 걸고자하는 객체를 지정해주며 이 블럭의 영역 안으로 들어가면서 부터 쓰레드는 지정된 객체의 lock을 얻게 되고, 이 블럭을 벗어나면 lock을 반납합니다.
synchronized (객체의 참조변수) {
....
}
두 가지 방법 모두 lock의 획득과 반납이 자동적으로 이루어지므로 우리가 해야 할 일은 그저 임계구역만 지정해주는것입니다.
임계 영역은 멀티쓰레드 프로그램의 성능을 좌우하기 때문에 가능하면 메소드 전체에 락을 거는 것보다 synchronized 블럭으로 임계구역을 최소화해서 보다 효율적인 프로그램이 되도록 노력해야한다.
아래의 예제는 동기화 하지않은 코드입니다. 실행 결과를 보면 통장의 잔고가 음수가 되는것을 확인할 수 있습니다. 이런 결과의 이유는 한 쓰레드가 if 문의 조건식을 통과하고 출금하기 바로 직전에 다른 쓰레드가 끼어들어서 출금을 먼저 했기 때문입니다.
public class ThreadExample {
public static void main(String[] args) {
Runnable r = new MyThread_1();
new Thread(r).start();
new Thread(r).start();
}
}
class Account {
private int balance = 1000;
public int getBalance() {
return balance;
}
public void withdraw(int money) {
if (balance >= money) {
try {
Thread.sleep(1000);
}catch (InterruptedException e) {
}
balance -= money;
}
}
}
class MyThread_1 implements Runnable {
Account acc = new Account();
@Override
public void run() {
while (acc.getBalance() > 0) {
// 100, 200, 300중의 한 값을 임의로 선택해서 출금(withdraw)
int money = (int) (Math.random() * 3 + 1) * 100;
acc.withdraw(money);
System.out.println("balance:" + acc.getBalance());
}
}
}

위의 코드에서 문제를 해결하는것은 간단합니다. withdraw() 메소드에 synchronized 키워드를 사용해서 임계구역으로 지정해주면 더이상 음수값이 나타나지 않습니다.
public synchronized void withdraw(int money) {
.....
}
public class ThreadExample {
public static void main(String[] args) {
Runnable r = new MyThread_1();
new Thread(r).start();
new Thread(r).start();
}
}
class Account {
private int balance = 1000;
public int getBalance() {
return balance;
}
public synchronized void withdraw(int money) {
if (balance >= money) {
try {
Thread.sleep(1000);
}catch (InterruptedException e) {
}
balance -= money;
}
}
}
class MyThread_1 implements Runnable {
Account acc = new Account();
@Override
public void run() {
while (acc.getBalance() > 0) {
// 100, 200, 300중의 한 값을 임의로 선택해서 출금(withdraw)
int money = (int) (Math.random() * 3 + 1) * 100;
acc.withdraw(money);
System.out.println("balance:" + acc.getBalance());
}
}
}
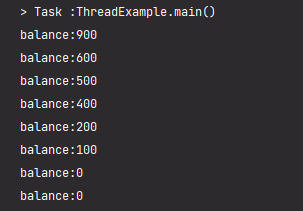
synchronized 블록으로 만들어도 같은 결과를 얻을 수 있습니다. 아래는 withdraw 안의 작업을 synchronized 블록으로 감싼 코드입니다.
public void withdraw(int money) {
synchronized(this) {
if (balance >= money) {
try { Thread.sleep(1000); } catch (Exception e) { }
balace -= money;
}
}
}
wait()와 notify()
synchronized로 동기화하면 공유 데이터를 보호할 수 있지만 특정 쓰레드가 객체의 락을 가진 상태로 오랜시간을 보내지 않게 하는것도 중요합니다.
-> 만일 계좌에 입금할 돈이 부족해서 한 쓰레드가 락을 보유한 채로 돈이 입금될 때까지 오랜 시간을 보낸다면, 다른 쓰레드들은 모두 해당 객체의 락을 기다리느라 다른 작업들도 원활히 진행되지 않을 것입니다.
이런 상황을 wait()와 notify()를 이용해 해결할 수 있습니다.
동기화된 임계구역의 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니라면, wait()를 호출하여 쓰레드가 락을 반납하고 기다리게 합니다. 이때 다른 쓰레드가 락을 얻어 해당 객체에 대한 작업을 수행할 수 있게 됩니다. 이후 작업을 다시 진행할 수 있는 상황이 되면 notify()를 호출해서, 작업을 중단했던 쓰레드가 다시 락을 얻어 작업을 진행할 수 있습니다.
wait(), notify(), notifyAll()
- Object에 정의 되어 있는 메소드 입니다.
- 동기화 블록(synchronized블록)내에서만 사용할 수 있습니다.
- 보다 효율적인 동기화를 가능하게 합니다.
wait() : 쓰레드가 락을 반납하고 기다리게 합니다.
notify() : 객체의 대기실에서 대기중인 모든 쓰레드중 임의의 쓰레드에게 lock을 얻을 수 있는 상태로 바꿔줍니다.
notifyAll() : 기다리고 있는 모든 객체에게 통지하여 lock을 얻을 수 있는 상태로 바꿔줍니다. notifyAll()이 호출된 객체의 waiting pool에 대기중인 쓰레드만 해당됩니다.
아래의 코드는 음식(dish)을 만들어서 테이블(Table)에 추가하는 요리사(Cook)와 테이블의 음식을 소비하는 손님(Customer)을 쓰레드로 구현한 코드입니다.
import java.util.ArrayList;
public class ThreadExample {
public static void main(String[] args) throws Exception{
Table table = new Table();
new Thread(new Cook(table), "COOK1").start();
new Thread(new Customer(table, "donut"), "CUSTOMER1").start();
new Thread(new Customer(table, "burger"), "CUSTOMER2").start();
Thread.sleep(2000);
System.exit(0);
}
}
class Customer implements Runnable {
private Table table;
private String food;
Customer(Table table, String food) {
this.table = table;
this.food = food;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(100);
}catch (InterruptedException e) {
}
String name = Thread.currentThread().getName();
table.remove(food);
System.out.println(name + " ate a " + food);
}
}
}
class Cook implements Runnable {
private Table table;
Cook(Table table) {this.table = table; }
@Override
public void run() {
while (true) {
int idx = (int) (Math.random()*table.dishNum());
table.add(table.dishNames[idx]);
try {
Thread.sleep(10);
}catch (InterruptedException e) { }
}
}
}
class Table {
String[] dishNames = { "donut", "donut", "burger" };
final int MAX_FOOD = 6;
private ArrayList<String> dishes = new ArrayList<>();
public synchronized void add(String dish) {
while (dishes.size() >= MAX_FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name+" is waiting.");
try {
wait(); // COOK쓰레드를 기다리게 합니다.
Thread.sleep(500);
}catch (InterruptedException e) { }
}
dishes.add(dish);
notify(); // 기다리고 있는 CUSTOMER를 깨우기 위함.
System.out.println("Dishes:" + dishes.toString());
}
public void remove(String dishName) {
synchronized (this) {
String name = Thread.currentThread().getName();
while (dishes.size() == 0) {
System.out.println(name+" is waiting.");
try {
wait(); // CUSTOMER 쓰레드를 기다리게 합니다.
Thread.sleep(500);
}catch (InterruptedException e) { }
}
while (true) {
for (int i = 0; i < dishes.size(); i++) {
if (dishName.equals(dishes.get(i))) {
dishes.remove(i);
notify(); // 잠자고 있는 COOK 쓰레드를 깨우기 위함
return;
}
} // for문의 끝
try {
System.out.println(name+ " is waiting.");
wait();
Thread.sleep(500);
}catch (InterruptedException e) {
}
}
}
}
public int dishNum() { return dishNames.length; }
}

만약 테이블에 손님이 원하는 음식이 없는 상태라면 손님은 테이블 객체의 lock을 가진채로 무한정 기다리게 될것입니다. 요리사 쓰레드가 음식을 새로 추가하려고 해도 테이블 객체의 lock을 손님이 가지고있어서 불가능합니다. 이때 손님 쓰레드를 wait()로 lock을 풀고 기다리다가 음식이 추가되면 notify()로 통보를 받고 다시 lock을 얻어서 음식을 먹도록 구현할 수 있습니다.
Lock 과 Condition 을 이용한 동기화
오래 기다린 쓰레드가 notify()로 인해 락을 얻는다는 보장은 없습니다. wait()가 호출되면, 실행 중이던 쓰레드는 해당 객체의 대기실(waiting pool)에서 통지를 기다립니다. notify()가 호출되면, 해당 객체의 대기실에 있는 모든 쓰레드 중에서 임의의 쓰레드만 통지를 받습니다. notifyAll()을 해서 모든 쓰레드에게 통보를 해도 lock을 얻는것은 하나의 쓰레드뿐이기 떄문에 다른 쓰레드들은 계속해서 lock을 기다려야 합니다.
-> 이처럼 운이 나쁘면 계속 lock을 얻지못하고 오랫동안 기다리게 되는 형상을 '기아(starvation) 현상'이라고 합니다.
기아 현상을 막으려면 notifyAll()을 호출해서 모든 쓰레드에게 통지하면 손님 쓰레드는 다시 waiting pool에 들어가더라도 요리사 쓰레드는 결국 lock을 얻어서 작업을 진행 할 수 있습니다. 하지만 모든 쓰레드가 통지를 받기 때문에 불필요한 쓰레드까지 lock을 얻으려고 하기 때문에 여러 쓰레드가 lock을 얻기위해 경쟁하게 됩니다. 이렇게 여러 쓰레드가 lock을 얻기 위해 경쟁하는 것을 '경쟁 상태(race confition)'라고 합니다.
Lock 과 Condition을 이용하면 선별적인 통지가 가능합니다.
Lock클래스들을 이용하면 동기화를 할 수 있습니다.
synchronized블럭으로 동기화하면 자동적으로 lock이 잠기고 풀리고 예외가 발생해면 lock은 자동적으로 풀리기 때문에 편리합니다. 그러나 같은 메서드 내에서만 lock을 걸 수 있다는 제약이 때로는 불편하기도 합니다.
그럴 때 Lock클래스를 사용합니다.
Lock클래스의 종류 3가지
- ReetrantLock : 재진입이 가능한 lock. 가장 일반적인 배타 lock
- ReentrantReadWriteLock : 읽기에는 공유적이고, 쓰기에는 배타적인 lock
읽기를 위한 lock과 쓰기를 위한 lock을 제공합니다.
읽기 lock이 걸린 상태에서 동시에 여러 쓰레드가 읽기 lock을 얻는것은 가능합니다. 하지만 읽기 lock이 걸린 상태에서 다른 쓰레드가 쓰기 lock을 거는것은 불가능하고 반대의 경우도 마찬가지 입니다.
읽기를 할 때는 읽기 lock을 걸고, 쓰기를 할 때는 쓰기 lock을 거는것을 제외하면 lock을 거는 방법은 같습니다. - StampedLock : ReentrantReadWriteLock에 낙관적인 lock의 기능을 추가
lock을 걸거나 해제할 때 '스탬프(long타입의 정수값)'를 사용하며 읽기와 쓰기를 위한 lock외에 '낙관적 읽기 lock(optimistic reading lock)' 이 추가된 것입니다. 읽기 lock이 걸려있으면 쓰기 lock을 얻기 위해서는 읽기 lock이 풀릴 때 까지 기다려야 하지만 '낙관적 읽기 lock'은 쓰기 lock에 의해 바로 풀립니다.
아래는 StampedLock을 이용한 낙관적 읽기의 예 입니다.
int getBalance() {
long stamp = lock.tryOptimisticRead(); // 낙관적 읽기 lock을 건다.
int curBalance = this.balance; // 공유 데이터인 balance를 읽어온다.
if (lock.validate(stamp)) { // 쓰기 lock에 의해 낙관적 읽기 lock이 풀렸는지 확인
stamp = lock.readLock(); // lock이 풀렸으면, 읽기 lock을 얻으려고 기다린다.
try {
curBalance = this.balance; // 공유 데이터를 다시 읽어온다.
} finally {
lock.unlockRead(stamp); // 읽기 lock을 푼다.
}
}
return curBalance; // 낙관적 읽기 lock이 풀리지 않았으면 곧바로 읽어온 값을 반환
}
ReentrantLock
ReentrantLock의 생성자
- ReentrantLock() : 기본 생성자
- ReentrantLock(boolean fair) : 인자로 true 값을 주면, lock이 풀렸을 때 가장 오래 기다린 쓰레드가 lock을 획득할 수 있게, 즉 공정(fair)하게 처리합니다. (공정하게 처리하려면 어떤 쓰레드가 가장 오래 기다렸는지 확인해야하는 작업을 거쳐야 하기 때문에 선능은 떨어집니다.)
ReentrantLock의 메소드
- void lock() : lock을 잠금
- void unlock() : lock을 해제합니다.
- boolean isLocked() : lock이 잠겼는지 확인합니다.
-> synchronized블럭과 달리 Lock클래스들은 수동으로 lock을 잠그고 해제해야 합니다. lock을 잠그고 푸는것은 메소드만 호출하면 되지만 lock을 걸고나서 푸는 것을 잊어버리는 실수를 하지 않도록 주의해야 합니다.
임계 구역 내에서 예외가 발생하거나 return문으로 빠져 나가게 되면 lock이 풀리지 않을 수 있으므로
unlock()은 try-finally문으로 감싸는 것이 일반적입니다.
ReentrantLock lock = new ReentrantLock();
...
lock.lock();
try{
// 임계 구역 작업 코드
} finally {
lock.unlock();
}
대부분의 경우 synchronized블럭을 사용할 수 있으며, 그럴 때는 그냥 synchronized블럭을 사용하는 것이 더 나을 수 있습니다.
이외에도 tryLock() 이라는 메소드가 있습니다. 이 메소드는 lock() 메소드와 달리, 다른 쓰레드에 의해 lock이 걸려있으면 lock을 얻으려고 기다리지 않습니다. 또는 지정된 시간 만큼만 기다립니다. lock을 얻으면 true, 그렇지 않으면 false를 반환합니다.
boolean tryLock()
boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException
lock() 메소드는 lock을 얻을 때까지 쓰레드를 블락(block) 시키므로 쓰레드의 응답성이 나빠질 수 있습니다.
응답성이 중요한 경우, tryLock()을 이용해서 지정된 시간동안 lock을 얻지 못하면 다시 작업을 시도할지 포기할지 사용자가 결정할 수 있게 하는것이 응답성이 좋은 쓰레드를 만드는 것입니다.
-> 또한 이 메소드는 interruptException을 발생 시킬 수 있는데 이는 지정된 시간동안 기다리는 중 interrupt()에 의해 작업이 취소될 수 있도록 코드를 작성할 수 있다는 뜻입니다.
Lock 클래스를 try-with-resource를 이용해서 자동으로 unlock() 호출하기
lock을 걸고 푸는것을 잊어버리는 실수를 하지 않도록 try-with-resource를 이용한다면 어떨까 해서 코드를 짜봤습니다. AutoUnlockReentrantLock 클래스를 만들어서 AutoCloseable close 메소드에서 unlock() 메소드를 호출하도록 했습니다. 이렇게 사용해도 큰 장점은 없는것 같습니다..
package study10th;
import java.util.concurrent.locks.ReentrantLock;
public class LockTest {
public static void main(String[] args) {
Runnable r = new MyThread_1();
new Thread(r).start();
new Thread(r).start();
}
}
class Account {
private int balance = 1000;
private AutoUnlockReentrantLock lock = new AutoUnlockReentrantLock();
public int getBalance() {
return balance;
}
public void withdraw(int money) {
try(AutoUnlockReentrantLock closeableLock = lock.open()) {
if (balance >= money) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
balance -= money;
}
}catch (Exception e) { }
}
}
class MyThread_1 implements Runnable {
Account acc = new Account();
@Override
public void run() {
while (acc.getBalance() > 0) {
int money = (int) (Math.random() * 3 + 1) * 100;
acc.withdraw(money);
System.out.println("balance:" + acc.getBalance());
}
}
}
class AutoUnlockReentrantLock extends ReentrantLock implements AutoCloseable {
public AutoUnlockReentrantLock open() {
this.lock();
return this;
}
@Override
public void close() throws Exception {
this.unlock();
}
}
ReentrantLock과 Condition
Condition은 wait()와 notify의 단점인 쓰레드를 구분해서 통지하지 못하기 때문에 발생하는 '경쟁 상태'의 단점을 해결해줍니다.
Condition을 이용하면 각각의 waiting pool에서 쓰레드의 종류에 따라 구분하여 넣을 수 있습니다.
그냥 사용한다고 경쟁 상태가 완전히 없어지는 것은 아니지만 좀 더 세분화하여 waiting pool을 나눌 수록 경쟁 상태가 발생할 가능성을 낮게 할 수 있습니다.
이전의 요리사와 손님, 그리고 테이블을 이용한 코드를 예로들면 아래와 같이 사용할 수 있습니다.
private ReentrantLock lock = new ReentrantLock(); // lock을 생성
// lock으로 condition을 생성
private Condition forCook = lock.newCondition();
private Condition forCustomer = lock.newCondition();
Object의 wait()와 notify() 메소드와 대응하는 Condition의 메소드는 다음과 같습니다.
| Object | Condition |
| void wait() | void await() void awaitUninterruptibly() |
| void wait(long timeout) | boolean await(long time, TimeUnit unit) long awaitNanos(long nanosTimeout) boolean awaitUntil(Date deadline) |
| void notify() | void signal() |
| void notifyAll() | void signalAll() |
간단하게 생각하면 wait() & notify() 대신 Condition의 await() & signal() 을 사용한다고 생각하면 됩니다.
아래는 이전의 예제에서 add 메소드에 await()와 notify() 대신 await()와 signal()을 사용한 코드입니다.
전에는 wait()와 notify만 사용하면서 대상이 무엇인지 보이지 않았지만 await()와 signal()은 forCook.await() / forCust.signal()과 같이 사용해서 대기와 통지의 대상이 명확하게 보이는 장점이 있습니다.
public add(String dish) {
lock.lock();
try {
while (dished.size() >= MAX_FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name+" is waiting.");
try {
forCook.await(); // wait(); COOK 쓰레드를 기다리게 합니다.
} catch (InterruptedException e) { }
}
dished.add(dish);
forCust.signal(); // notify(); 기다리고 있는 CUST를 깨우기 위함.
System.out.println("Dished:" + dishes.toString());
}finally {
lock.unlock();
}
}데드락(교착상태, DeadLock)
교착상태란?
2개 이상의 프로세스가 다른 프로세스의 작업이 끝나기만 기다리며 작업을 더 이상 진행하지 못하는 상태를 교착 상태(dead lock)라고 합니다. 교착 상태의 가장 좋은 예로 사용되는 식사하는 철학자 문제로 설명하겠습니다.


이 문제는 철학자들이 둥근 테이블에 앉아 식사를 하는데 각자의 자리의 왼쪽에 있는 젓가락을 잡은 뒤 오른쪽의 젓가락도 잡아야만 식사가 가능하다는 조건이 있습니다. 모든 철학자들은 왼쪽의 젓가락을 잡고 오른쪽을 쳐다보면 왼손에 젓가락을 들고 오른쪽을 쳐다보고 있는 다른 철학자가 보일것입니다. 결국 오른쪽 젓가락을 잡지 못해 모두 굶어 죽게 될것입니다.
오른쪽 그림은 식사하는 철학자 문제를 자원 할당 그래프로 나타낸 것입니다. P1~P4는 프로세스(또는 쓰레드)를 나타내고 R1~R4는 공유 자원을 의미합니다.
교착 상태가 발생하는 원인
교착상태가 발생하기 위해서는 아래의 4가지 조건을 만족해야 합니다.
이 4가지 조건을 교착 상태의 필요조건 이라고 합니다.
1. 상호 배제 : 철학자들은 서로 포크를 공유할 수 없습니다.
-> 자원을 공유하지 못하면 교착 상태가 발생합니다. 여기서 자원은 배타적인 자원이어야 합니다. 배타적인 자원은 임계구역에서 보호되기 때문에 다른 프로세스(쓰레드)가 동시에 사용할 수 없습니다.
2. 비선점 : 각 철학자는 다른 철학자의 포크를 빼앗을 수 없습니다.
-> 자원을 빼앗을 수 없드면 자원을 놓을 때까지 기다려야 하므로 교착상태가 발생합니다.
3. 점유와 대기 : 각 철학자는 왼쪽 포크를 잡은 채 오른쪽 포크를 기다립니다.
-> 자원 하나를 잡은 상태에서 다른 자원을 기다리면 교착 상태가 발생합니다.
4. 원형 대기 : 자원 할당 그래프가 원형입니다.
-> 자원을 요구하는 방향이 원을 이루면 양보를 하지 않기 때문에 교착상태가 발생합니다.
교착 상태 해결방법
| 해결 방법 | 특징 |
| 교착 상태 예방 | 교차 상태를 유발하는 네 가지 조건을 무력화합니다. |
| 교착 상태 회피 | 교착 상태가 발생하지 않는 수준으로 자원을 할당합니다. |
| 교착 상태 검출 | 자원 할당 그래프를 사용하여 교착 상태를 발견합니다. |
| 교착 상태 회복 | 교착 상태를 검출한 후 해결합니다. |
- 교착 상태 예방
교착 상태는 상호 배제, 비선점, 점유와 대기, 원형 대기 라는 네 가지 조건을 동시에 충족해야 발생하기 때문에 이 중 하나라도 막는다면 교착 상태가 발생하지 않습니다. 그러나 이 방법은 실효성이 적어 잘 사용되지 않습니다. - 교착 상태 회피
자원 할당량을 조절하여 교착 상태를 해결하는 방식입니다. 즉, 자원을 할당하다가 교착 상태를 유발할 가능성이 있다고 판단하면 자원 할당을 중단하고 지켜보는 것입니다. 그러나 자원을 얼마만큼 할당해야 교착 상태가 발생하지 않는다는 보장이 없기 때문에 실효성이 적습니다. - 교착 상태 검출과 회복
교착 상태 검출은 어떤 제약을 가하지 않고 자원 할당 그래프를 모니터링 하면서 교착 상태가 발생하는지 살펴보는 방식입니다. 만약 교착 상태가 발생하면 교착 상태 회복 단계가 진행됩니다.
교착 상태를 검출한 후 이를 회복시키는 것은 결론적으로 교착 상태를 해결하는 현실적인 접근 방법입니다.
fork & join 프레임워크
10년 전까지만 해도 CPU의 속도는 매년 거의 2배씩 빠르게 향상되어왔습니다.
그러나 이제 그 한계에 도달하여 속도 보다는 코어의 개수를 늘려서 CPU의 성능을 향상시키는 방향으로 발전해가고 있습니다. 이런 하드웨어의 변화에 맞춰 프로그래밍도 멀티 코어를 잘 활용할 수 있는 멀티 쓰레드 프로그래밍이 점점 더 중요해지고 있습니다. 하지만 멀티 쓰레드 프로그래밍은 쉽지 않습니다.
JDK 1.7부터 'fork & join 프레임워크' 가 추가 되어, 하나의 작업을 작은 단위로 쪼개서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 줍니다.
수행할 작업에 따라 아래의 두 클래스 중에서 하나를 상속받아 구현하면 됩니다.
RecursiveAction 반환값이 없는 작업을 구현할 때 사용
RecursiveTask 반환값이 있는 작업을 구현할 때 사용
Runnable에 run() 메소드가 있는것처럼 위의 두 클래스를 상속받아 compute() 라는 추상 메소드에 작업할 내용으로 재정의 하면 됩니다. 아래는 1부터 n까지의 합을 계산한 결과를 반환하는 RecursiveTask를 상속받은 SumTask 클래스입니다.
class SumTask extends RecursiveTask<Long> {
long from, to;
SumTask(long from, long to) {
this.from = from;
this.to = to;
}
public Long compute() {
long size = to - from + 1;
if (size <= 5) // 더할 숫자가 5개 이하면
return sum(); // 숫자의 합을 반환
long half = (from + to) / 2;
// 범위를 반으로 나눠서 두개의 작업을 생성
SumTask leftSum = new SumTask(from, half);
SumTask rightSum = new SumTask(half+1, to);
leftSum.fork();
return rightSum.compute() + leftSum.join();
}
long sum() {
long tmp = 0L;
for (long i = from; i <= to; i++) {
tmp += i;
}
return tmp;
}
}
쓰레드를 시작할 때 start() 메소드를 호출하듯이 쓰레드 풀을 생성해 invoke() 메소드를 호출해서 작업을 시작합니다.
ForkJoinPool pool = new ForkJoinPool(); // 쓰레드 풀을 생성
SumTask task = new SumTask(from, to); // 수행할 작업을 생성
Long result = pool.invoke(task); // invoke() 를 호출해서 작업을 시작
ForkJoinPool
fork&join프레임워크에서 제공하는 쓰레드 풀(thread pool)입니다.
장점
- 지정된 수의 쓰레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게 합니다.
- 쓰레드를 반복해서 생성하지 않아도 됩니다.
- 너무 많은 쓰레드가 생성되어도 성능 저하가 발생하는 것을 막아줍니다.
- 쓰레드 풀은 기본적으로 코어의 개수와 동일한 개수의 쓰레드를 생성합니다.
Compute()의 구현
compute()를 구현할 때는 수행할 작업 외에도 작업을 어떻게 나눌 것인가에 대해서도 구현해야합니다.
public Long compute() {
long size = to - from + 1;
if (size <= 5) { // 더할 숫자가 5개 이하면
return sum(); // 숫자의 합을 반환. sum()은 from부터 to까지의 수를 더해서 반환
}
// 범위를 반으로 나눠서 두 개의 작업을 생성
long half = (from + to) / 2;
// 절반을 기준으로 나눠 left, right 로 작업의 범위를 반으로 나눠서 새로운 작업으로 생성합니다.
SumTask leftSum = new SumTask(from, half); // 시작부터 절반지점 까지
SumTask rightSum = new SumTask(half+1, to); // 절반지점부터 끝까지
leftSum.fork(); // 작업(leftSum)을 작업 큐에 넣습니다.
return rightSum.compute() + leftSum.join();
}
compute()의 구조를 보면 일반적인 재귀 호출 메소드와 같습니다.
아래 그림은 위의 코드를 그림으로 표현한 것입니다. 그림에서는 size가 2가 될때까지 작업을 나눕니다. (코드에서는 5가 될 때까지 작업을 나눕니다.)
간단하게 말하면 compute()는 작업을 반으로 나눕니다. fork()는 작업 큐에 작업을 담습니다.
또한 fork()의 호출로 작업 큐에 담긴 작업 역시 compute()로 인해 반으로 목표한 작은 size까지 작업을 나눕니다.
이러한 작업을 반복하다 보면 여러개의 작은 단위로 작업을 나눌 수 있습니다.

아래 그림은 compute() 메소드와 fork() 메소드로 인해 작업풀에 담긴 작업이 쓰레드 풀(thread pool)의 빈 쓰레드가 작업을 가져와서 작업을 수행하는 것을 나타낸 그림입니다. 이렇게 빈 쓰레드가 작은 단위의 작업을 가져와서 작업을 수행하는 것을 작업 훔쳐오기(work stealing)라고 하며, 이 과정은 모두 쓰레드 풀에 의해 자동으로 이루어 집니다.
이런 과정을 통해 한 쓰레드에 작업이 몰리지 않고 여러 쓰레드가 골고루 작업을 나누어 처리하게 됩니다.
물론 작업의 크기가 충분히 작게 나눠져야 여러 쓰레드에게 작업을 골고루 나눠줄 수 있습니다.

fork() 와 join()
fork()는 작업을 쓰레드의 작업큐에 넣는 것이고, join()은 작업의 결과를 반환합니다.
fork()와 join()의 차이점
fork() : 해당 작업을 쓰레드 풀의 작업큐에 넣습니다. 비동기 메소드(asynchronous method)
join() : 해당 작업의 수행이 끝날 때까지 기다렸다가, 수행이 끝나면 그 결과를 반환합니다.동기 메소드(synchronous method)
비동기 메서드는 일반적인 메소드와 달리 메소드를 호출만 하고 결과를 기다리지 않습니다.
-> 내부적으로 다른 쓰레드에게 작업을 수행하도록 지시만 하고 결과를 기다리지 않고 돌아오는 것입니다.
그래서 fork()를 호출하면 기다리지 않고 다음 줄의 명령을 실행합니다. 위의 코드에서는 바로 return 문으로 넘어갑니다.
"return rightSum.compute() + leftSum.join();" 이 return 문에서 compute()가 재귀호출 될 때, join()은 호출되지 않습니다. compute()로 더이상 작업을 나눌 수 없게 됐을 때 join()의 결과를 기다렸다가 더해서 결과를 반환합니다.
즉, 재귀 호출된 모든 compute()가 모두 종료될 때, 최종 결과를 얻습니다.
아래의 코드는 fork & join 프레임워크를 이용해 1부터 100,000,000 까지의 합을 구하는 것과 단순 for문을 이용해 합을 구하는 것의 시간을 비교하는 코드입니다. 흥미로운 실행결과가 있습니다.
package study10th;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinTest {
static final ForkJoinPool pool = new ForkJoinPool(); // 쓰레드 풀을 생성
public static void main(String[] args) {
long from = 1L;
long to = 100_000_000L;
SumTask task = new SumTask(from, to);
long start = System.currentTimeMillis(); // 시작시간 초기화
long result = pool.invoke(task);
System.out.println("Elapsed time(6 Core) : " + (System.currentTimeMillis() - start));
System.out.printf("sum of %d~%d=%d%n", from, to, result);
System.out.println();
result = 0L;
start = System.currentTimeMillis(); // 시작시간 초기화
for (long i = from; i <= to; i++) {
result += i;
}
System.out.println("Elapsed time(1 Core) : " + (System.currentTimeMillis() - start));
System.out.printf("sum of %d~%d=%d%n", from, to, result);
}
}
class SumTask extends RecursiveTask<Long> {
long from, to;
SumTask(long from, long to) {
this.from = from;
this.to = to;
}
public Long compute() {
long size = to - from + 1;
if (size <= 5) // 더할 숫자가 5개 이하면
return sum(); // 숫자의 합을 반환
long half = (from + to) / 2;
// 범위를 반으로 나눠서 두개의 작업을 생성
SumTask leftSum = new SumTask(from, half);
SumTask rightSum = new SumTask(half+1, to);
leftSum.fork();
return rightSum.compute() + leftSum.join();
}
long sum() {
long tmp = 0L;
for (long i = from; i <= to; i++) {
tmp += i;
}
return tmp;
}
}

ForkJoinPool로 계산한 결과보다 단순 for문으로 계산한 결과가 시간이 덜 걸린것을 확인할 수 있습니다.
이것은 작업을 나누고 합치는데 걸리는 시간이 있기 때문입니다. 재귀호출이 for문보다 빠른 것과 같은 이유인데, 항상 멀티 쓰레드로 처리하는 것이 빠르다고 생각해서는 안됩니다.
-> 반드시 테스트 해보고 이득이 있을 때만, 멀티쓰레드로 처리해야 합니다.
참고문헌
- docs.oracle.com/javase/8/docs/api/
- docs.oracle.com/javase/8/docs/api/java/lang/Runnable.html
- www.tcpschool.com/java/java_thread_concept
- 자바의 정석 3판
- 쉽게 배우는 운영체제
'java-liveStudy' 카테고리의 다른 글
| 12주차. 애너테이션 (0) | 2021.01.31 |
|---|---|
| 11주차. Enum (0) | 2021.01.24 |
| 9주차 과제. 예외 (0) | 2021.01.16 |
| 8주차. 인터페이스 (0) | 2021.01.09 |
| 7주차. 패키지 (0) | 2021.01.01 |




댓글